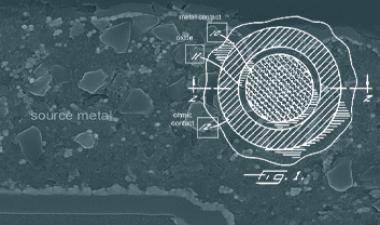
发布日期:2019年4月11日
撰稿人:Dick James,Jeongdong Choe
去年周日晚上,TechInsights在IEDM举办了一个招待会,Arabinda Das和Jeongdong Choe发表了演讲,吸引了一屋子与会者。阿拉辛达是第一个站出来的,在苹果iPhone十年历程与半导体技术创新”接着是郑东讨论”记忆过程、设计和架构:今天和明天”.
Arabinda大致回顾了iPhone及其功能组件的顺序开发过程——我们往往忘记了第一款iPhone没有摄像头、指纹传感器、人脸识别等,因此这绝对是一次记忆之旅。
Jeongdong介绍了逆向工程专家所看到的最新内存技术,对他们最近的分析进行了相当详细的总结,我想在本文中介绍一下。郑东是该公司的高级技术研究员,也raybet正规么是他们的内存技术主题专家。在加入TechInsights之前,他曾担任SK Hynix和三星推进下一代存储设备研发的团队负责人,因此他知道自己在说什么。
NAND闪存技术
我们开始看看NAND闪存,截至2018年11月,前六大制造商的市场份额分别为三星36%、东芝19%、西部数字(WD)15%、美光13%、SK Hynix 11%和英特尔6%。
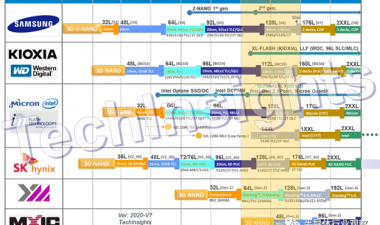
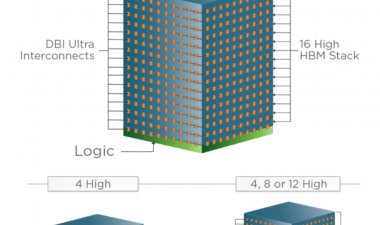
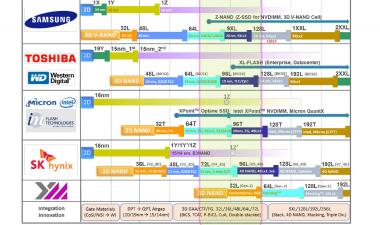
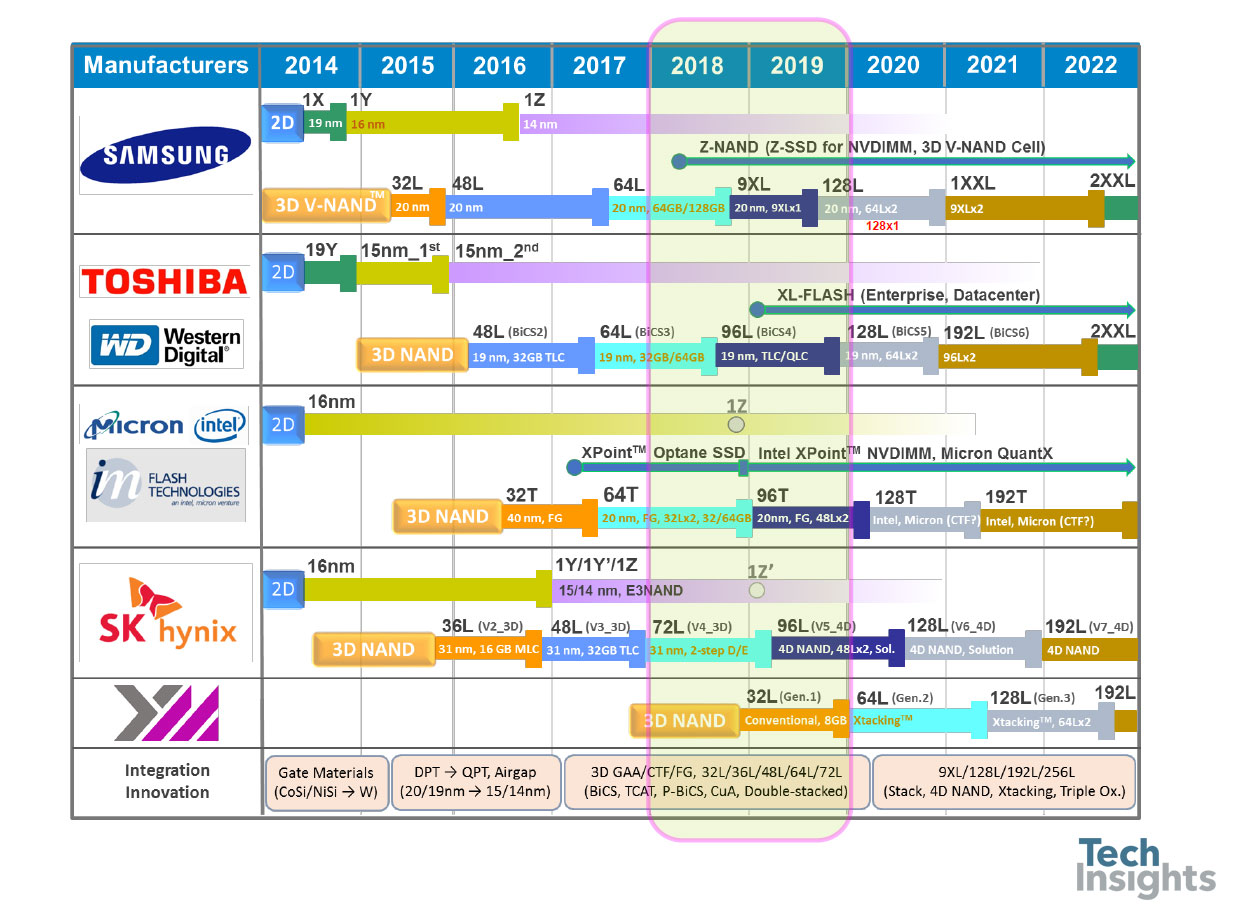
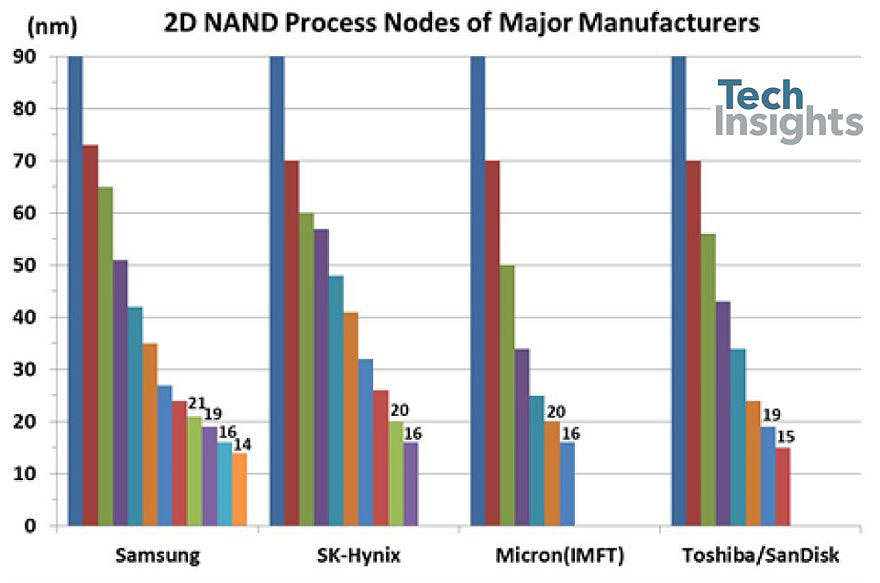
Jeongdong每年都会为内存生成路线图,下面是NAND闪存的更新路线图。你可以看到我们现在进入了1z纳米平面闪光的时代(可能是13-14纳米,因为1y是~15纳米),而且~96层3D闪光灯,具有四级细胞。路线图是基于已发表的预测,但我发现很难相信仅仅三年我们就能达到200+层。
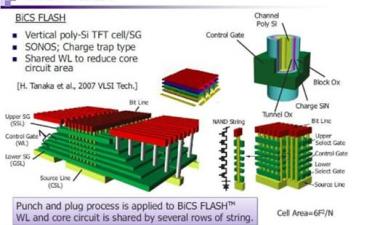
在图的底部是过去几年的技术演变,从平面器件中的控制栅从硅化物到钨的转变开始;然后我们从双图案到四图案,当我们得到低于20nm的特征尺寸时。我们看到了气隙的广泛采用(实际上,微米是从25nm一代开始的),随着15/16nm平面零件的全面生产,3D/V-NAND产品也随之推出。它们使用了两种存储技术,电荷阱(将电荷存储在氮化硅层上——三星、东芝/WD和SK-Hynix)和浮栅(微米/Intel)。
9X层3D NAND分析-了解更多
下载我们的3D NAND分析概述,包括市场概述、NAND技术路线图、模具图像,以及我们可以应用于这些产品的不同分析方法的概要。
Micron/Intel还使用了一种不同的布局理念,这种布局理念提供了更大的区域数据密度;他们设计了堆栈,使驱动电路位于阵列下,节省了外围区域,并使芯片更小——他们称之为CMOS阵列下(CuA)。他们的64层产品是2x32堆栈,96层使用2x48层堆栈。
展望未来,路线图显示多达256层,平面将淡出除了利基应用。“4D NAND”似乎是SK Hynix版本的CuA,而Xtacking是YMTC(扬子内存技术有限公司)在阵列上堆叠CMOS以节省面积的工艺。
跟踪平面设备,我们有来自主要制造商的这个序列:

到目前为止看到的最小半间距是三星14-NM 128-GB模具,块尺寸为152个细胞:
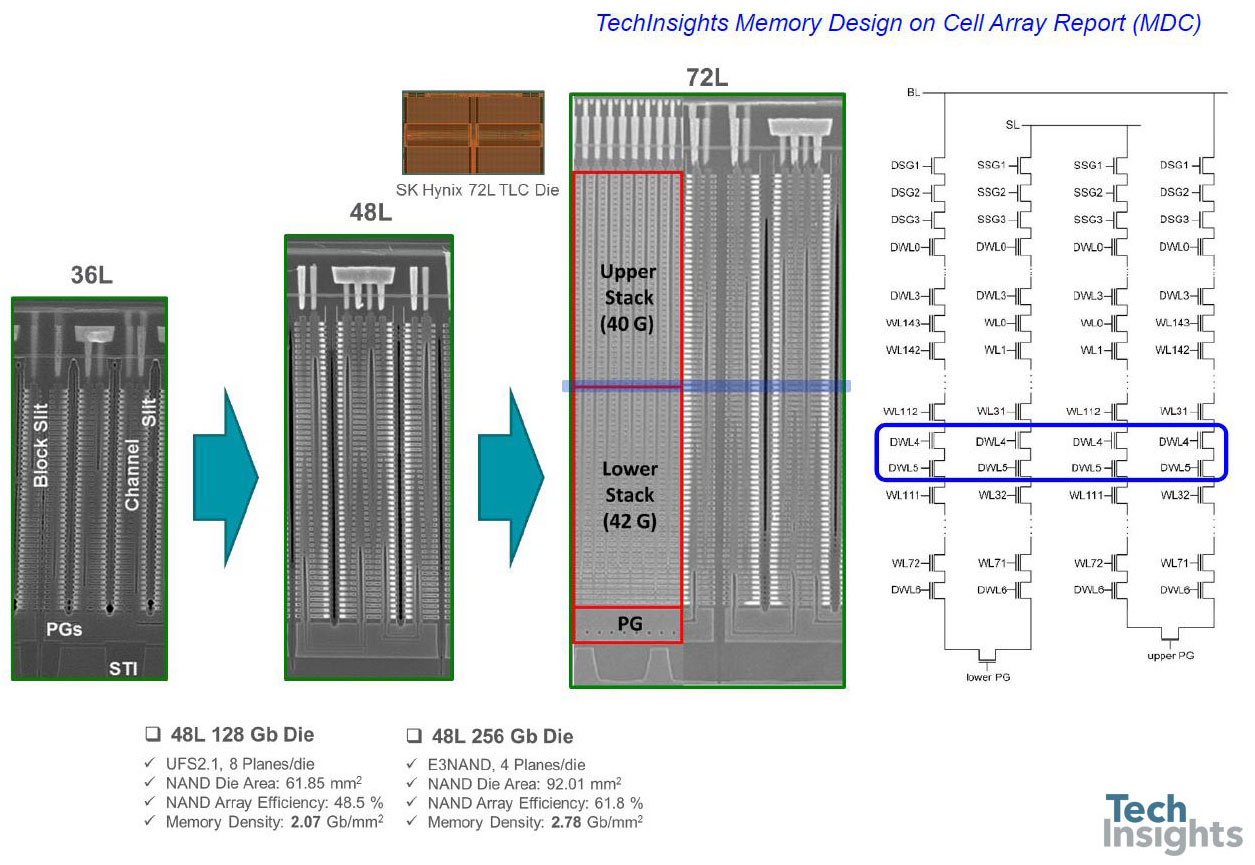
3D NAND:64L和72L(256 GB和512 GB)
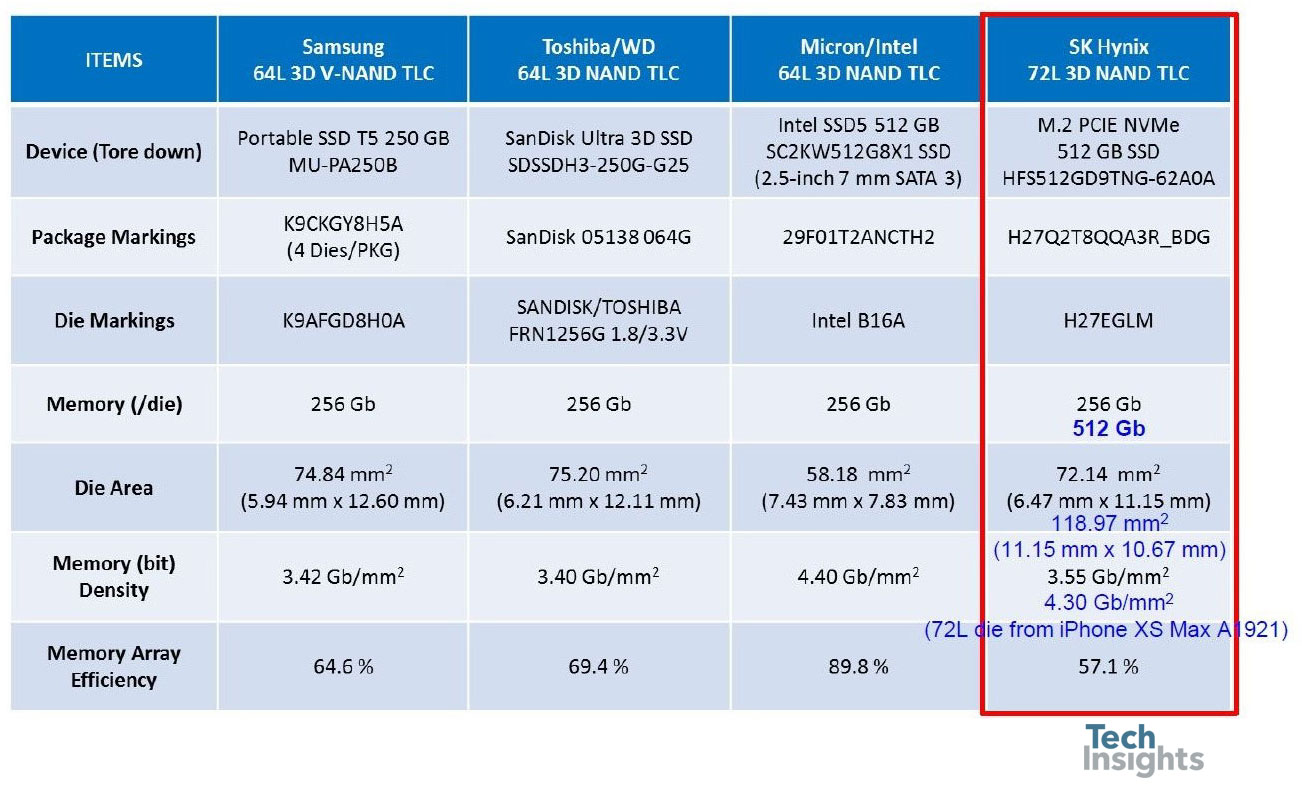
切换到3D-NAND,Jeongdong向我们展示了最近64层和72层设备的总结:

我们可以看到Intel部分中的CuA如何将阵列效率提高到几乎90%,从而获得256 Gb组中最小的芯片。iphonexsmax的SK Hynix 512gb芯片具有几乎相同的内存密度,与256gb芯片相比有了惊人的改进。
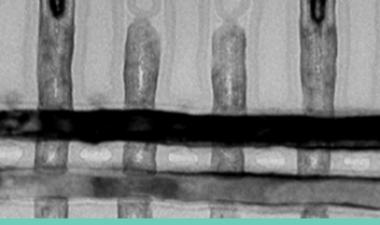
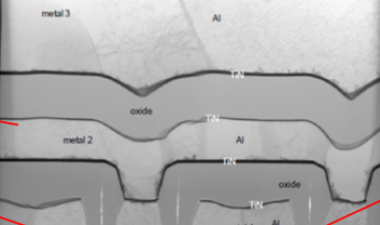
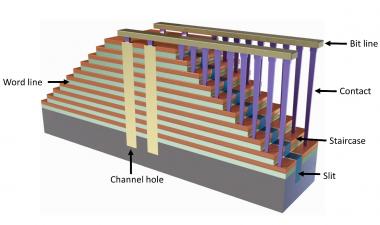
从48层技术过渡到64层技术的一个进展是蚀刻用于接触3D-NAND设备中字线的“楼梯”。例如,在东芝/WD零件中,由于蚀刻工艺的改进和修整掩模的改变,楼梯的宽度缩小了45%。

这不是不重要的,即使在收缩之后,楼梯也占据了0.82%的模具面积。同样,三星实现了27%的宽度缩减,楼梯的面积减少了0.44%。
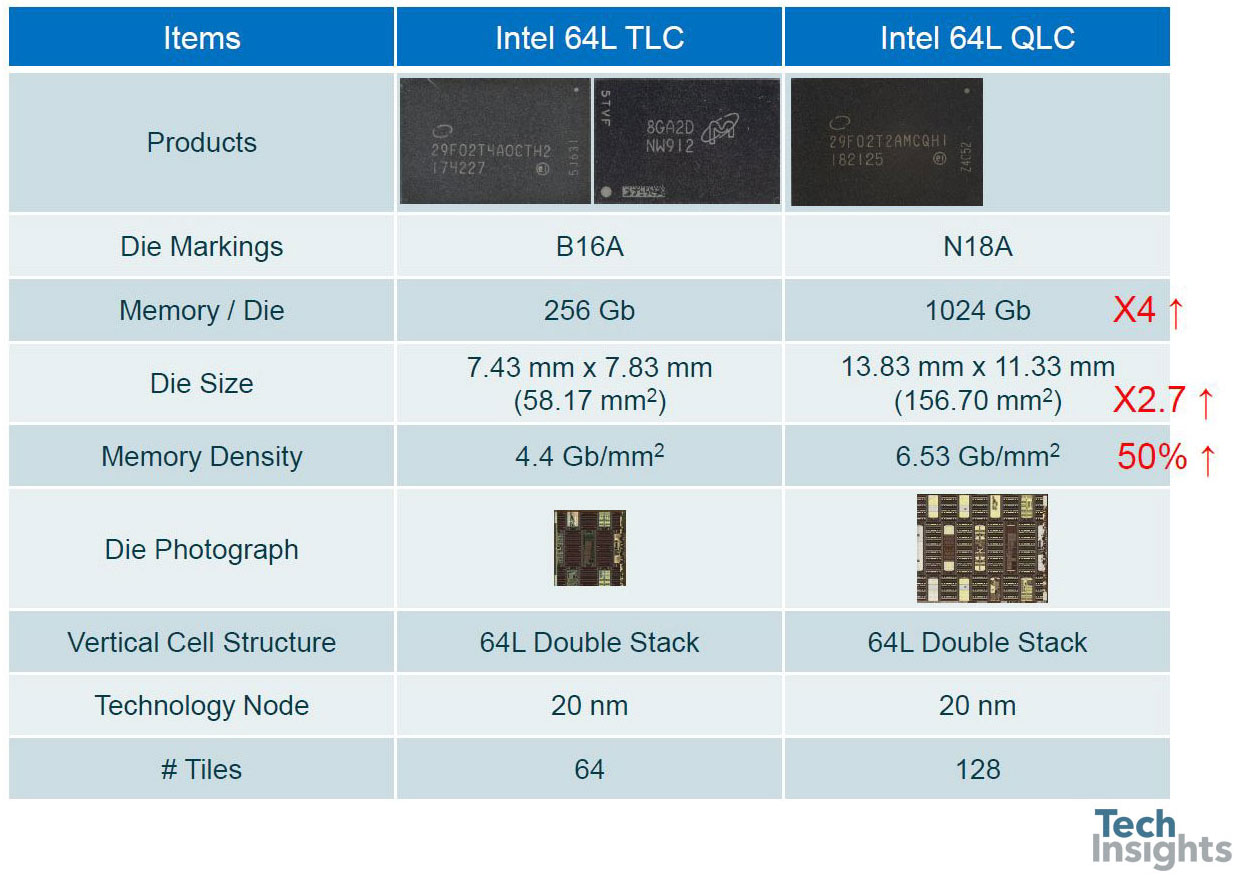
英特尔3D FG NAND QLC(64L):第一个3D QLC!
我们也有机会比较英特尔/微n’s tri-level and quad-level cell parts; even though they are both 20-nm, and both 64-level, the bit density goes from 4.4 to 6.5 Gb/mm2, an increase of almost 50%. We are now in the era of the terabit die, Micron has just announced 1-TB micro-SD cards with eight 1-Tb dies inside!
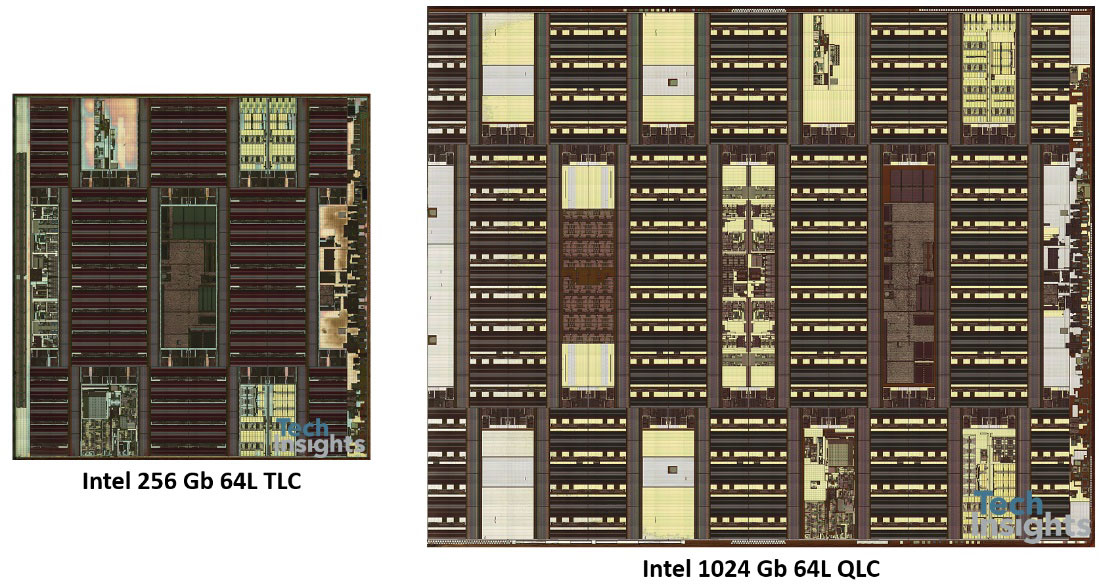
在上面的幻灯片中,晶体管级芯片的照片很小,但它们确实可以很好地缩小:
SK海力士72L P-BiCS
在这些照片中,我们可以清楚地看到阵列下面电路的密度。接下来是skhynix3d-NAND,它采用折叠结构。
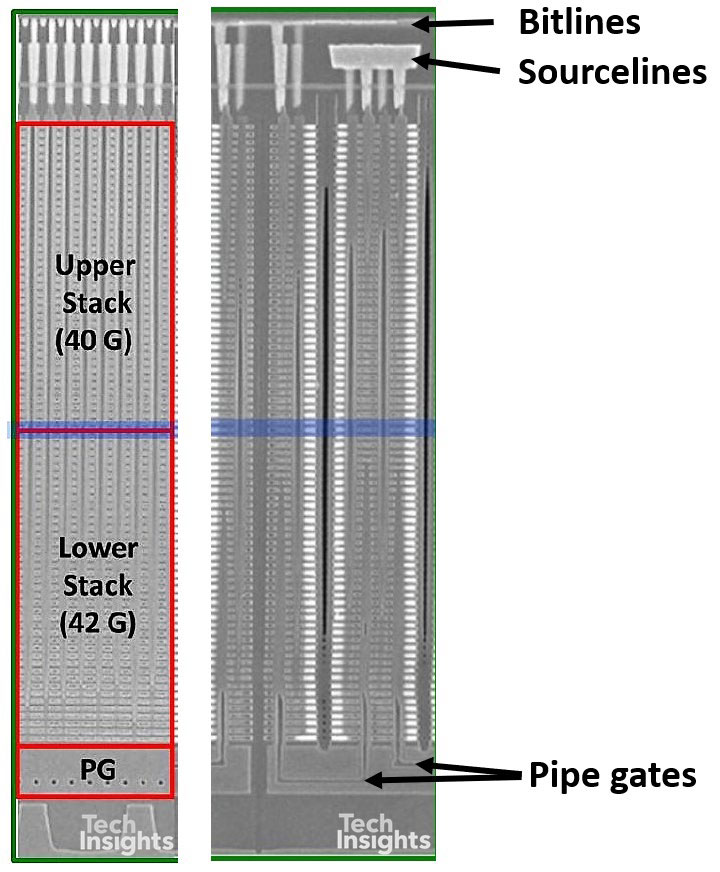
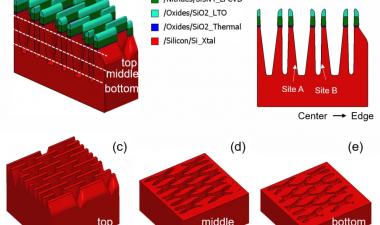
如果我们仔细观察,我们可以看到堆栈从36-48-72层的演变。36L设备只有一个通过门,而48L和72L有两个通过门,允许两个单元链使用公共位线和源线。72L堆栈的中心图像有点混乱,因为它有两个粘合在一起的正交图像–右侧是平行于位线的部分,左侧垂直于位线。如果我们查看分离的图像,PG区域中的孔显示左侧部分穿过两个管道门中的较低部分,并且在顶部可以看到单独的位线。
上下栈是指82门栈的两级结构。郑东在这次谈话中没有谈到这方面的细节,但他发表了一份声明blog on EETimeslast June that clarifies that the channel holes are formed with a two-step etching process. The estimated process sequence is:
- 管浇口模具成型(下部)
- Channel etching (lower portion, 42 gates)
- 孔内填充牺牲层
- 模具成型(上部)
- 通道蚀刻(上部,40门)
- 牺牲层去除
- 河道形成
狭缝和子狭缝是通过对整个叠层进行一步蚀刻而形成的。在上面的电路示意图中,蓝色轮廓显示了顶部和底部堆栈之间的两个虚拟字线的位置,由横截面中的蓝色线标记。
最后讨论的NAND设备是去年闪存峰会上展示的YMTC64L部件。这是他们的第二代3D-NAND技术,使用Xtacking将外围电路放在内存阵列的顶部而不是底部。YMTC采用面对面晶圆键合:

我对郑东使用的图像进行了注释,试图澄清我们所看到的:

3D NAND技术创新(今日)
我们在数组的边缘有一个典型的楼梯,他们有效地增加了每一步的字行数,向我们展示了在顶部有一个虚拟字行,在单独屏蔽的select门下面。
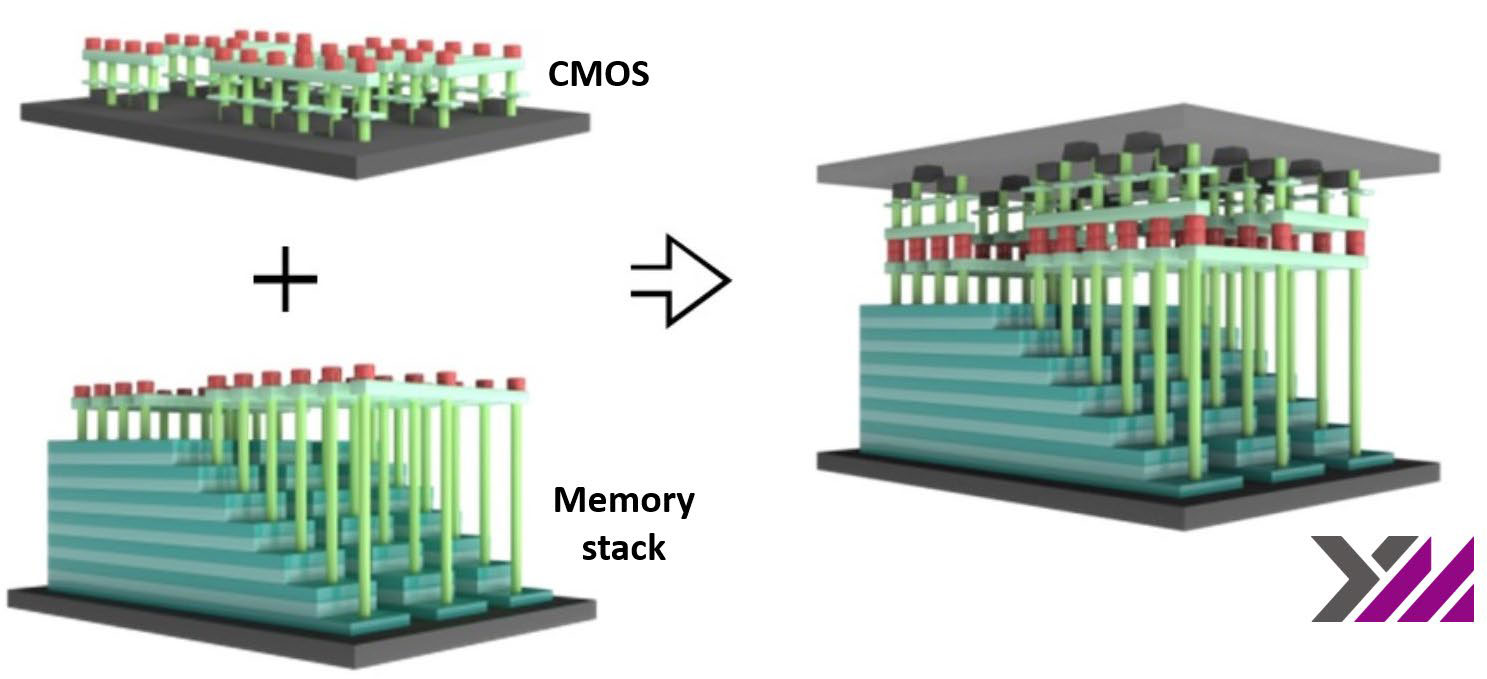
晶圆键合给我们提供了七个大马士革金属层,三个在阵列中,四个在CMOS中,在电池堆中有74个钨字线。YMTC的任何声明中都没有特别提到这一点,但从历史上看,他们一直与Spansion(现在的Cypress)密切合作,在NOR闪存中使用电荷陷阱存储,因此他们的3D-NAND似乎也是基于电荷陷阱的。
键合很可能是Xperi的DBI®(直接键合互连)技术–上面的TEM图像相当模糊,但它看起来确实与Sony IMX260堆叠图像传感器的SEM横截面中的界面相似,我们知道它使用了该过程。

如果我把先前的一张幻灯片排除在外,详细说明了SSD部分使用的Package-on-Package(PoP)的用法,我可能不是第一次使用PoP作为内存,但肯定不同于我们习惯在手机中看到的APU上的常规内存。这是由Microsoft Surface Pro提供的三星单包128 GB SSD:

我们在PoP的顶部有两个四层128 Gb V-NAND芯片,下部是一个4 Gb LPDDR4 DRAM和SSD控制器芯片。
郑东用两张总结幻灯片结束了NAND flash部分,这是迄今为止首次描述3D NAND的创新。这是一个繁忙的幻灯片,所以我不会详细介绍它-有很多创新!除了3D堆栈本身,可能还有一些意想不到的特性,比如外延(SEG)晶体管(Samsung)、CuA和双串堆栈(Micron)以及管栅(SK-Hynix)。现在我们有了晶圆键合!

摘要幻灯片跟踪了迄今为止的进展,并提出了对未来发展的一些担忧。
对我来说值得注意的是SK-Hynix回归到没有管栅的传统堆栈,微米(大概)回归到四个堆栈串,以及蚀刻和填充非常高宽高比通道的一般问题。
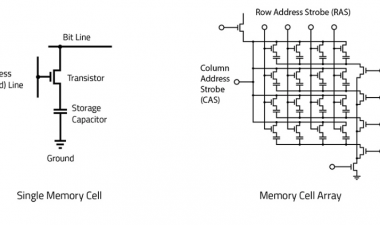
DRAM技术
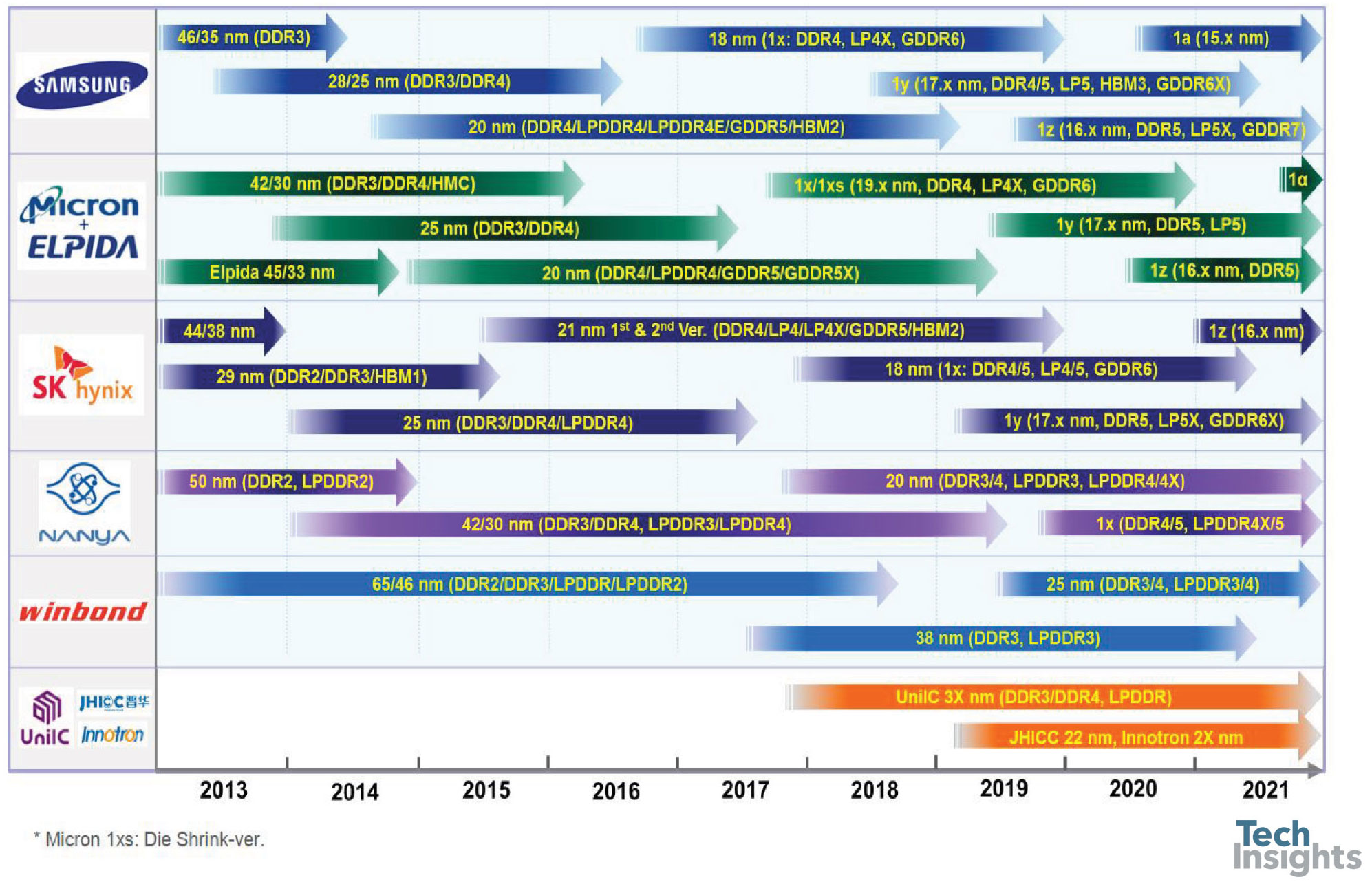
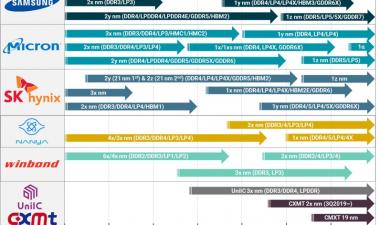
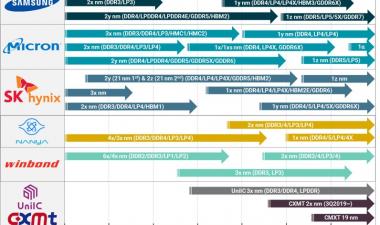
DRAM产品路线图更新
First up in the DRAM part of the talk was the roadmap:
我们现在已经进入1x nm世代,今年将推出17 nm部件。如果相信厂家的话,我们还是在一年的步调上进行下一次的推出收缩,虽然差距比较小,现在我们都在20nm以下。几年前,我倾向于认为,在1-something节点的技术达到极限之前,我们可能会有两代人,但现在看来,我们至少会看到四代人,这可能会让我们至少撑到2025年。
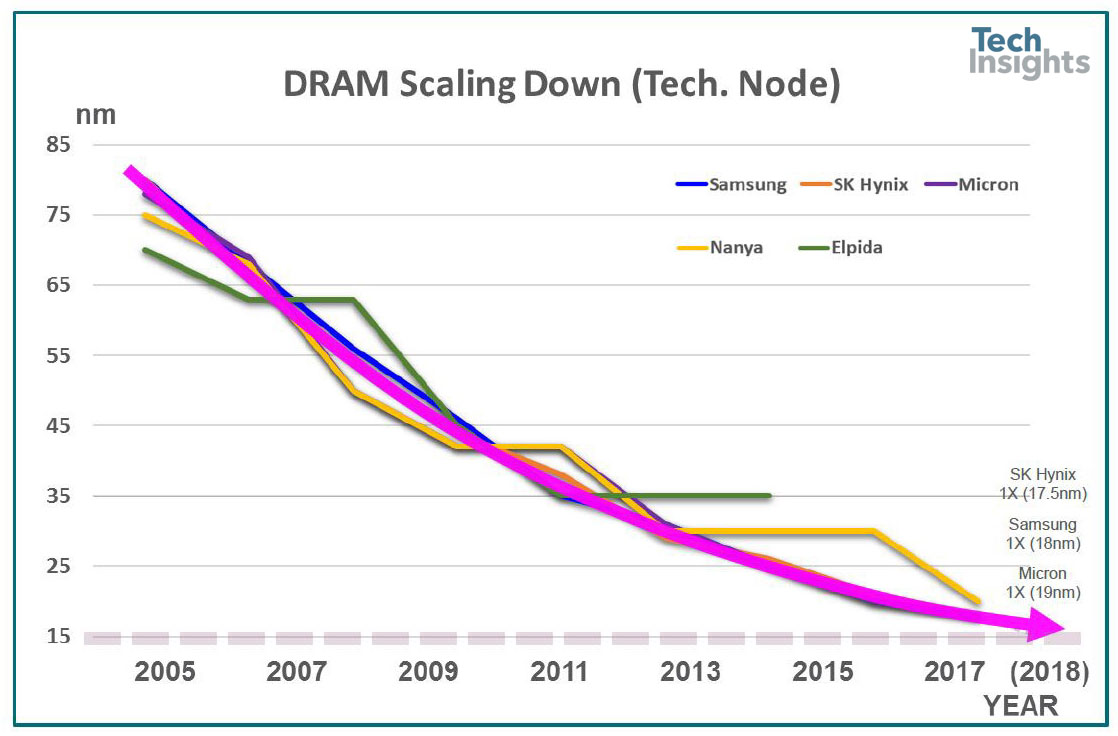
DRAM技术节点趋势
通过观察节点的时间趋势可以看出收缩率的减慢:
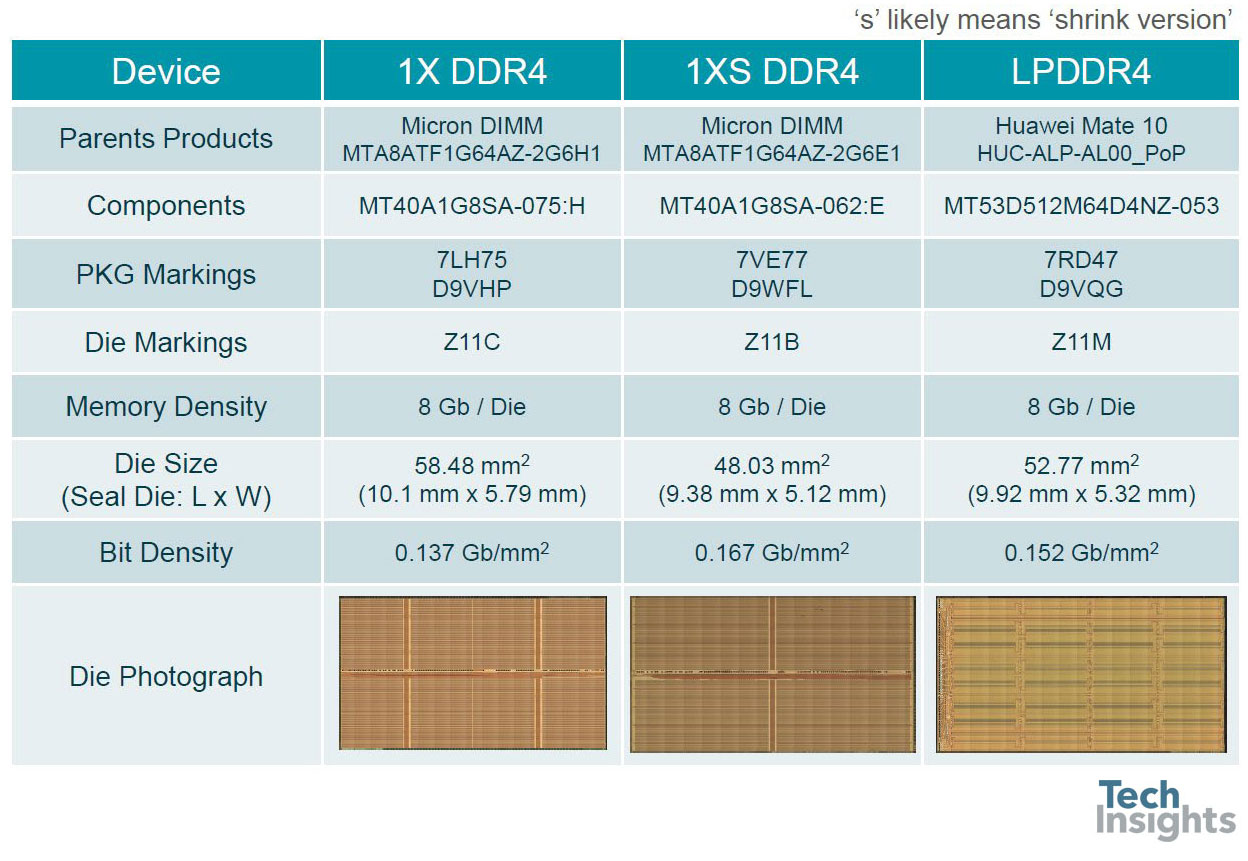
微米1X和1XS nm DDR4/LPDDR4
艾尔皮达在收购美光之前就已经停滞不前,纳亚也是如此。
Jeongdong还向我们介绍了最近的微米内存的一些细节,显示在8gb芯片中,它们的位密度现在高达0.167gb/mm2.
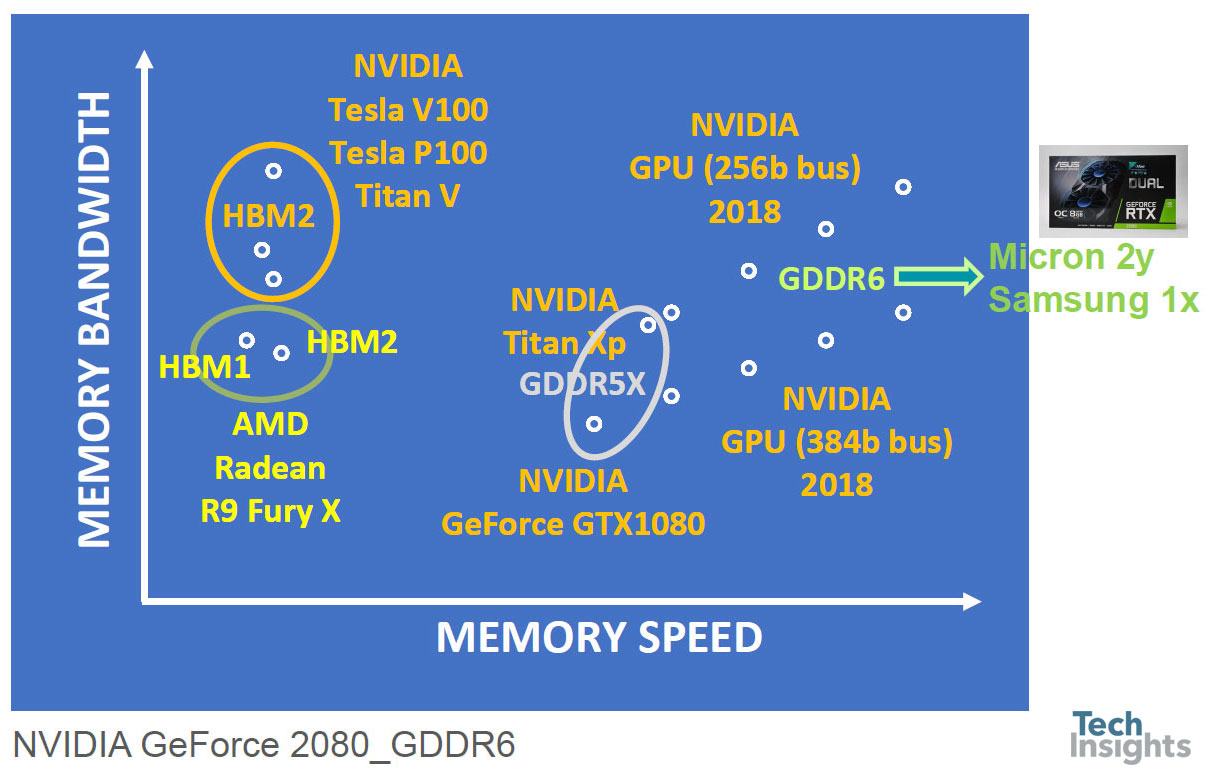
AMD和NVIDIA GPU卡摘要
然后看看AMD和Nvidia GPU,说明了使用HBM(高带宽内存)和HBM2时带宽的增加,以及从GDDR5X到GDDR6时带宽和速度的增加。
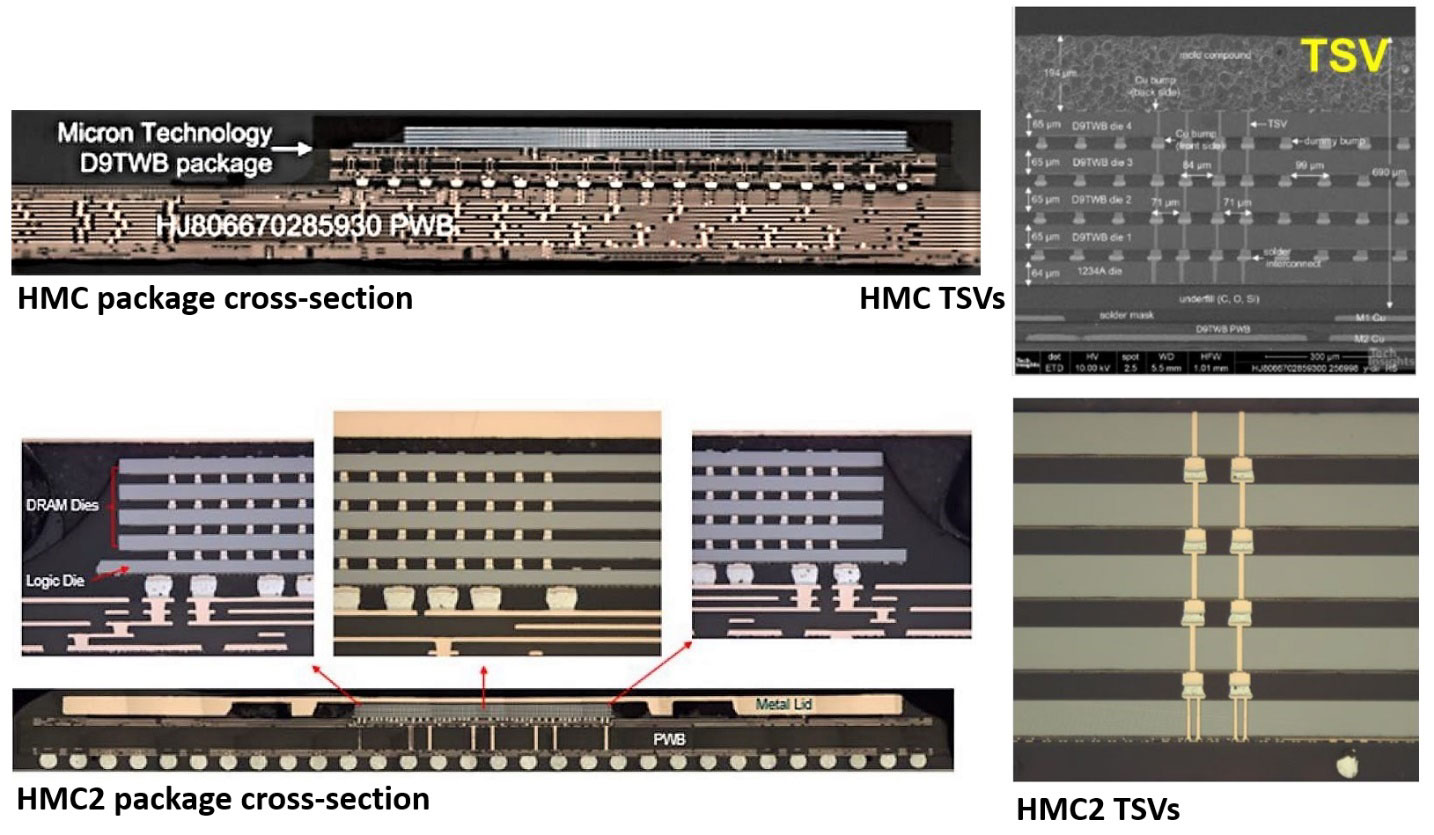
提到HBM让人想起了Micron的HMC(混合内存立方体),它现在已经演变成了HMC2。最初的HMC用于intelknight的Landing处理器,这是一种四栈DRAM,底部有一个IBM的fabbed控制器芯片,通过硅通孔(tsv)连接。HMC2似乎是作为一个独立的产品推出的,但仍然是一个带有控制器的4栈,HMC和HMC2都使用了30nm级DRAM。
HBM和HMC都使用TSV,但它们是不同的野兽;HMC具有其控制器管芯,并完全封装以安装在PCB基板上,而HBM与硅插入器一起使用。然而,Micron宣布它正在停止HMC,所以即使我们看过它,它也不会长时间左右。

ISP / DRAM / CIS(SONY)MICRON 35 NM(可能,ELPIDA FAB。)
DRAM部分的最后一张幻灯片介绍了索尼和三星公司为手机相机设计的带有CMOS图像传感器(CIS)和处理器(ISP)的DRAM的堆叠。在Sony IMX400中,DRAM夹在CIS和ISP之间;CIS面对面安装在DRAM上,DRAM与ISP面对面。堆栈中有DRAM允许相机系统以960帧/秒的速度运行,这是一种非常慢的运动能力。IMX400是在索尼Experia XZ手机上推出的,我们发表了一篇博客当时就在上面。

CIS/ISP/DRAM(三星)三星2y
三星S5K2L3 ISOCELL快速成像仪采用了不同的策略–CIS和ISP采用传统的面对面粘合方式,并使用TSV进行电气连接,标准DRAM芯片是在ISP上面对面微凸点连接。微凸点将DRAM上的重分布层(RDL)连接到ISP背面的基于Cu的RDL,后者将它们路由到tsv,通过ISP基板到达前端金属。DRAM芯片旁边还有一个虚拟硅芯片。
新兴存储器技术
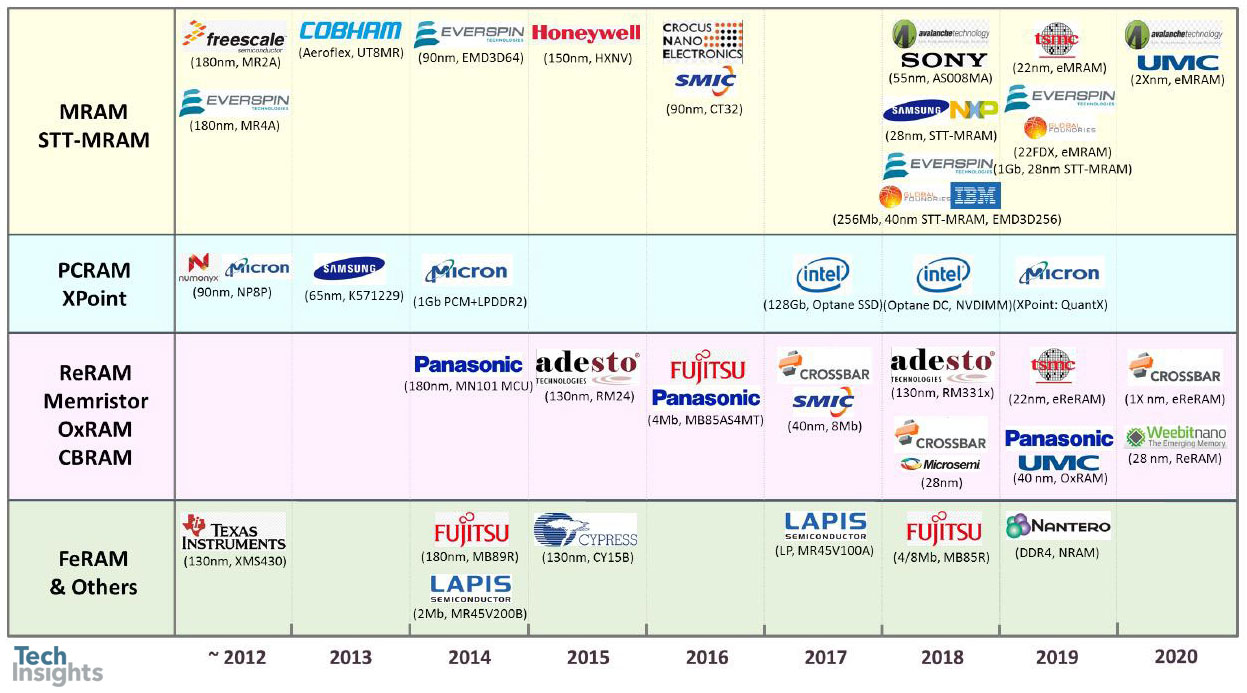
新兴内存大批量产品:主要参与者
郑东在结束他的演讲时回顾了新兴的记忆——尽管有些记忆是如何“新兴”的还有待讨论,因为有些产品已经存在了一段时间。以下是路线图:

Adesto Technologies CBRAM更新
例如。Everspin生产各种MRAM已经有一段时间了,相变存储器(PC-RAM)已经被许多公司在许多场合试用过,富士通已经生产了多年的FeRAM。
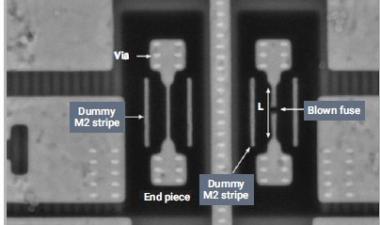
第一个例子是Adesto CBRAM(导电桥RAM),详细描述了第一代和第二代CB存储器之间的变化。

Everspin SST-MRAM 2型钕消息。
在结构上,桥层已经从银/硫化锗转变为碲基多层叠层,我认为这比银的温度敏感度低。
然后我们展示了256MB Everspin第二代STT-MRAM,采用DDR3格式的垂直MTJ(磁性隧道结)技术。
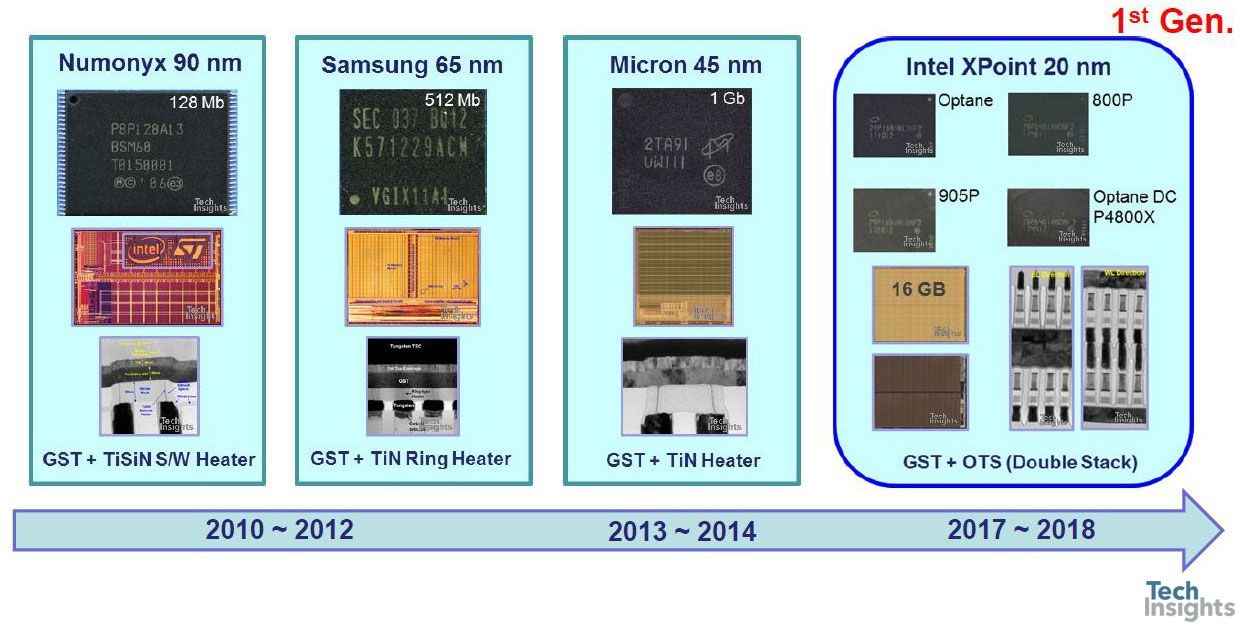
PCM商用产品:2010-2018
As a lead-up to the 3D-Xpoint slides which completed the talk, we were reminded that PC memory has been around for a while, and we have gone from 128 Mb from a 90-nm process to 20-nm 16 Gb:
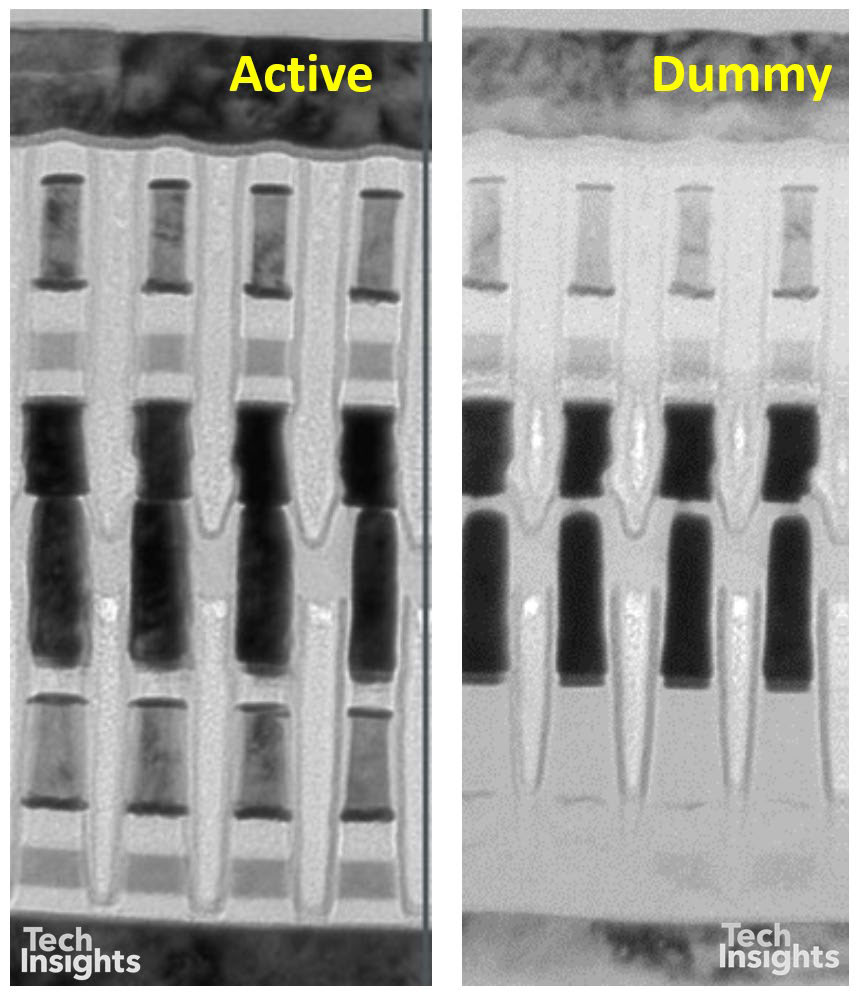
看来,至少在3D Xpoint的Intel Optane版本中,在内存级别(即金属4和金属5之间)有虚拟内存块,它们没有驱动电路,因此电路区域与内存阵列区域不同。存储单元的双层堆栈中也存在结构差异;在较低的单元中,似乎缺少存储层和选择器层(尽管此图像中有足够的阴影,因此消失的可能是样本制备人工制品)。然而,中间的钨丝字线是明显分开的。

这两层的堆叠当然增加了工艺的复杂性,因为我们必须加倍沉积、蚀刻和拍照步骤;在底层,字线位于堆栈的顶部,而顶部堆栈的字线位于底部,而位线则相反。
在M4和M5之间添加存储器图层为这些层之间的通孔结构提供了其他挑战,需要更多掩模层和相关成本。上部字线和比特素实际上是从下面连接的;作为示例,位线具有四个子孔的堆叠,以启动到顶部位线级别。
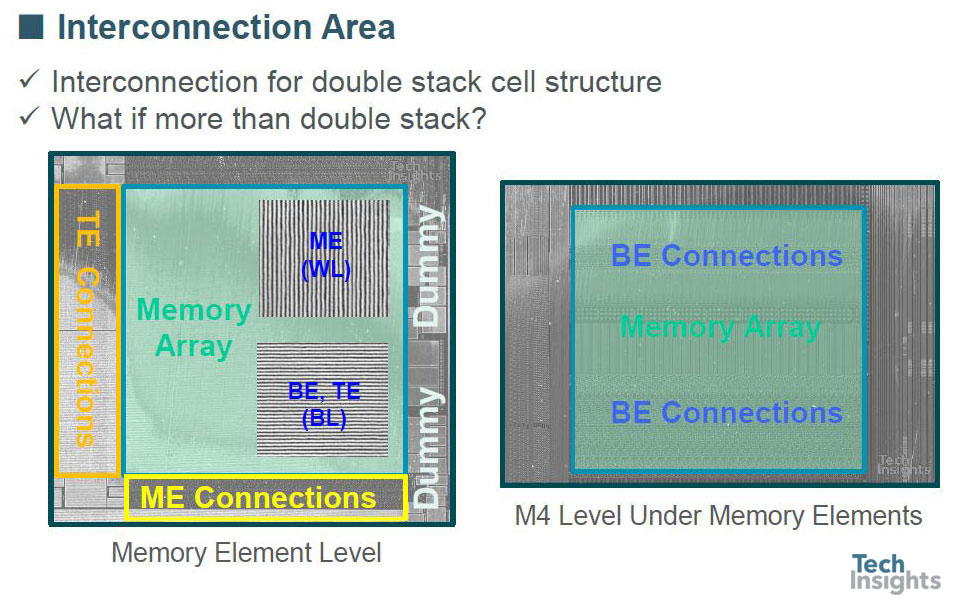
见解和问题:过程/设计视图
在平面图中,它看起来同样复杂,所以这就提出了一个问题——如果我们想使用一个以上的双层结构,我们该怎么办?(BE/ME/TE=底部/中间/顶部电极。)
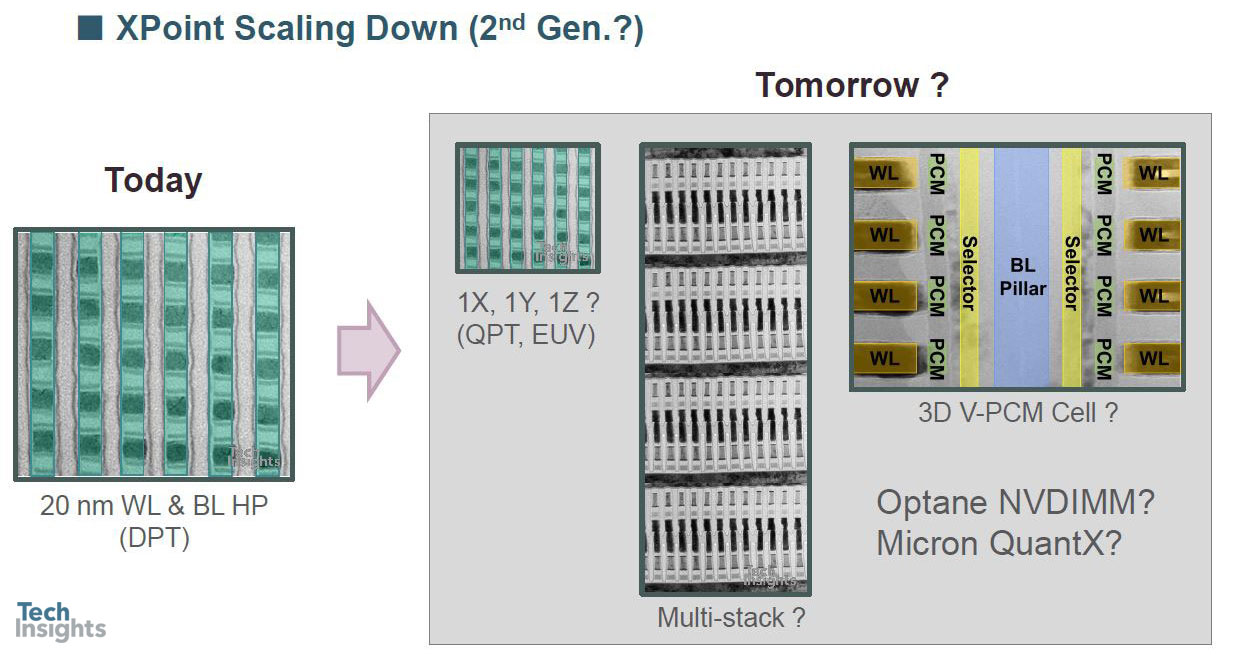
见解和问题:过程/设计视图
目前正在使用双图案,但当然有可能使用四重图案,甚至EUV,以及可能的多堆栈或3D结构;
演讲到此结束,但别忘了,所有这些信息,还有更多信息,都可以通过TechInsights的内存订阅.